
Aumenta il traffico del tuo sito. Gratis!
SEO tool gratis e strumenti SEO gratuiti, prova la nostra suite SEO ora!
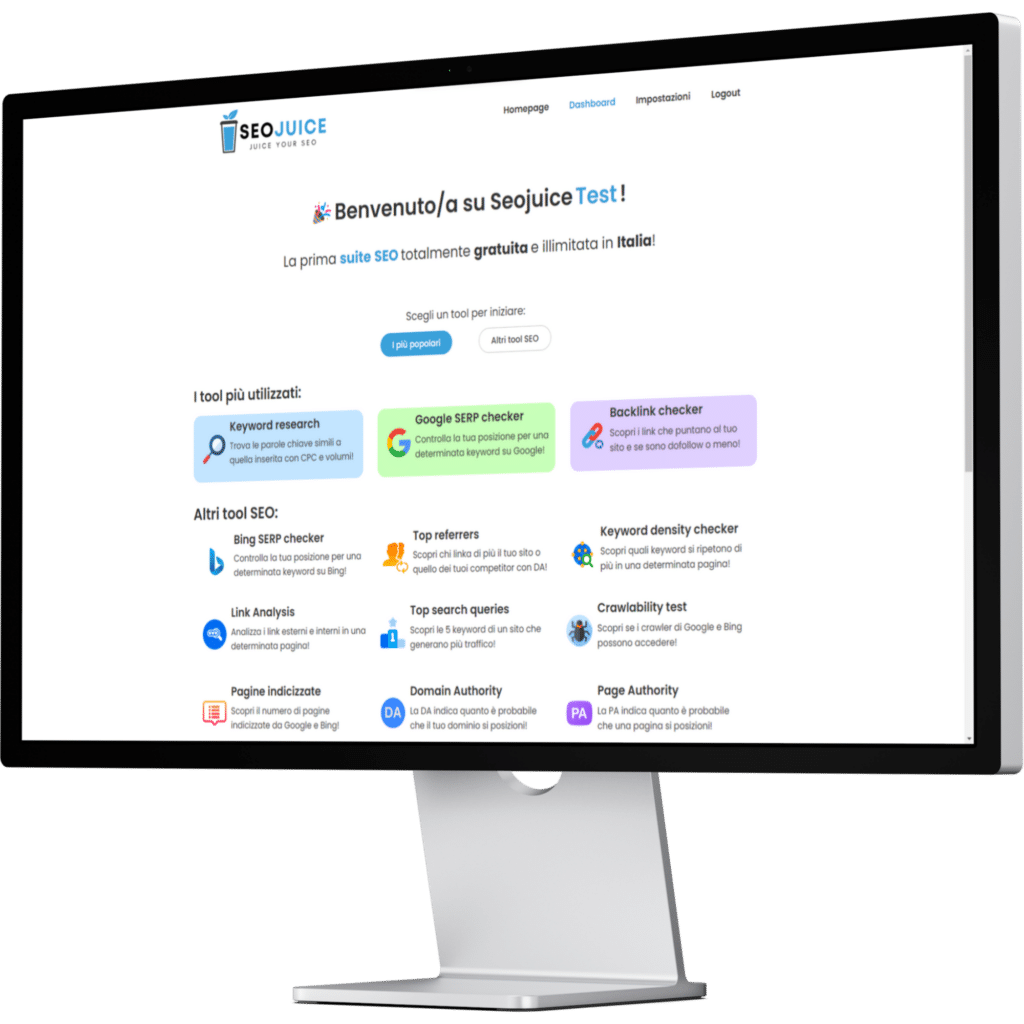
Ecco i nostri SEO tool 100% gratis!
Qui sotto troverai una selezione di strumenti SEO gratuiti sviluppati da noi. Ogni tool è gratis e pensato per aiutarti a ottimizzare il tuo sito senza spese.
Ecco qui di seguito una breve descrizione che spiega ogni tool SEO gratis!




Meta tag checker
Questo strumento mostra title, description e il numero di tag H1, H2 e H3.

Generatore long tail
Altro tool fondamentale, permette di trovare le long tail sfruttando Google Suggest.

Duplicati, link rotti e altro
Scova duplicati, link rotti e altro ed evita le penalizzazioni da parte di Google.

Generatore articoli SEO
Crea articoli ottimizzati SEO utilizzando le keyword da te scelte e suggerisce 3 titoli!

Spia i competitor
Scopri come si posizionano i competitor con PA, DA e backlink e ottieni un vantaggio!

Test velocità sito web
Misura quanto impiega a caricare il tuo sito web grazie a questo tool.






Pagine indicizzate
Questo tool ti indica il numero di pagine indicizzate da Google e Bing!

Domain Authority checker
Questo tool Indica la DA, ovvero quanto è probabile che il tuo dominio si posizioni!

Page Authority checker
Questo tool Indica la PA, ovvero quanto è probabile che una pagina si posizioni!
Parlano di noi:





Videorecensione: